Thoughts on systems design, backend engineering, AI, and the work of building useful products.
阐述 Chat Engine 作为查询引擎的有状态扩展形态,解决多轮连续对话场景。介绍 BaseChatEngine 统一接口及 AgentChatResponse 返回值结构。详解四种核心对话模式:① simple (纯聊天无检索);② condense_question (先改写问题再查询);③ context (直接检索再聊天);④ condense_plus_context (改写+检索+回答的组合模式)。重点分析 Memory 机制的 token 限额管理与自动裁剪策略。
定义 Query Engine 为 RAG 编排器,负责串联"Query → Retriever → Nodes → Synthesizer → Response"全流程。详解 RetrieverQueryEngine 的 4 步执行过程(接收问题→调用检索器→调用响应生成器→返回 Response),三种构造方式(index.as_query_engine / 指定参数 / 手动组装),以及四大扩展点(替换 Retriever/Synthesizer/增加 Postprocessor/改写 Query)。强调其作为"RAG 执行中枢"的核心价值。
详解 Synthesizer(响应生成器)的 6 种模式:① refine (迭代修正,逐个 Node 滚雪球式细化答案,适合超长上下文但成本高);② compact (紧凑打包,分组后合并局部答案,效率与效果平衡);③ simple_summarize (全部打包一次生成,快速但可能截断信息);④ tree_summarize (分治递归聚合,适合海量上下文);⑤ generation (不携带上下文,纯 LLM 回答);⑥ no_text (仅返回检索节点,不做生成)。每种模式均附 Prompt 设计分析与 Langfuse 链路图。
定义检索器的核心定位:决定 LLM 能看到什么上下文。介绍统一入口 retrieve() 的模板方法模式,以及各索引类型的检索模式差异:向量索引仅支持语义相似度检索;摘要索引支持 embedding/LLM 两种模式;对象索引依赖底层索引类型;知识图谱支持 5 种检索器(向量/同义词/Cypher/模板/自定义);树索引支持 4 种模式(LLM 遍历/向量遍历/全量叶/全量根);关键词表支持 3 种检索器。
介绍四种高级索引类型:① 文档摘要索引 (先概括再检索,适合宏观总结);② 对象索引 (将任意 Python 对象序列化后通过向量索引检索);③ 知识图谱索引 (PropertyGraphIndex 将非结构化文本转化为实体-关系三元组);④ 树索引 (层次化结构,叶子节点为原文,父节点为摘要)。每种类型均附原理图示与代码示例。
系统讲解 VectorStoreIndex 的三种构建方式:①从已有向量存储构造;②从 Node 列表构造(可指定 StorageContext 切换底层存储);③从文档直接构造(全自动流程)。详解 from_documents 内部工作流(分块→嵌入→写入→建索引),StorageContext 四组件职责(vector_store/docstore/index_store/graph_store),以及 as_retriever() 和 as_query_engine() 两条查询路径的区别。
解析 ChromaDB 向量数据库的核心概念(Collection/HNSW 索引/元数据过滤/持久化)及适用场景(RAG/语义搜索/推荐系统)。详细介绍 ChromaVectorStore 的初始化方式(PersistentClient/EphemeralClient/HttpClient)、向量存储与检索 API、stores_text 参数含义,以及底层数据持久化结构(SQLite + HNSW 文件)。
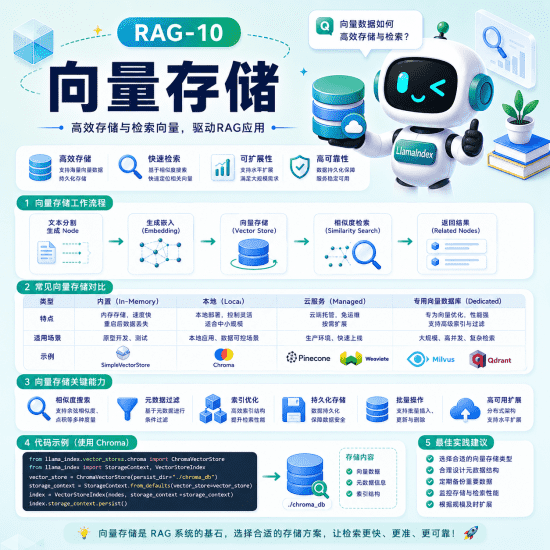
全面介绍向量存储的概念、职责(存储/检索/过滤)及相似度度量方法(余弦/L2/内积)。详解 SimpleVectorStore 的内存存储机制、JSON 持久化、暴力搜索查询流程,并列出优缺点。对比主流第三方向量库(Chroma/Qdrant/Milvus/Pinecone/FAISS/pgvector 等),给出不同场景的选择建议路径。